소개
이연습에서는 선형 회귀를 구현하고 데이터에서 작동하는 지 확인합니다. 이 프로그래밍 연습을 시작하기 전에 비디오 강의를 시청하고 관련 주제에 대한 리뷰 질문을 완료하는 것이 좋습니다.연습을 시작하려면 starter code 를 다운로드해야 합니다.코드를 작성하고 연습 내용을 완성하고자 하는 디렉토리에 압축을 풉니다. 필요한 경우 Octave 에서 cd 명령을 사용하여 이것을 변경하십시오. 디렉토리에 복사하십시오.
이 연습에 포함 된 파일
ex1.m - 운동을 통해 단계별로 도움이되는 옥타브 스크립트
ex1 multi.m - 연습의 뒷부분에 대한 옥타브 스크립트
ex1data1.txt - 하나의 변수를 사용한 선형 회귀에 대한 데이터 집합
ex1data2.txt - 여러 변수가있는 선형 회귀에 대한 데이터 집합
submit.m - 솔루션을 Google 서버로 보내는 제출 스크립트 <== 우리는 필요 없습니다.
[?] warmUpExercise.m - Octave의 간단한 예제 함수
[?] plotData.m - 데이터 세트를 표시하는 함수
[?] computeCost.m - 선형 회귀의 비용을 계산하는 함수
[?] gradientDescent.m - 그래디언트 강하를 실행하는 함수입니다.
[y] computeCostMulti.m - 여러 변수에 대한 비용 함수
[y] gradientDescentMulti.m - 여러 변수의 그라디언트 디센트
[y] featureNormalize.m - 지형지 물을 정규화하는 기능
[y] normalEqn.m - 정규 방정식을 계산하는 함수
? 완료해야 할 파일을 나타냅니다.
y는 추가 크레딧 연습을 나타냅니다.
연습을 하면서 ex1.m 및 ex1m.m이라는 스크립트를 사용하게 됩니다. 이 스크립트는 문제에 대한 데이터 세트를 설정하고
작성하는 함수를 호출합니다. 둘 중 하나를 수정할 필요가 없습니다. 이 과제의 지침에 따라 다른 파일의 기능 만 수정하면
됩니다.
이
프로그래밍 연습에서는 하나의 변수를 사용하여 선형 회귀를 구현하는 연습의 나머지 부분 만 완료하면됩니다. 연습의 두 번째
부분 (추가 크레딧으로 완료 할 수 있음)은 여러 변수가 있는 선형 회귀를 다룹니다.
1. 단순한 Octave 함수
ex1.m 의 첫 번째 부분에서는 Octave ( 옥 타브는 MATLAB의 무료 대안입니다. 프로그래밍 연습을 위해 Octave 또는 MATLAB을 자유롭게 사용할 수 있습니다 ) 구문과 숙제 제출 프로세스를 연습합니다. warmUpExercise.m 파일에는 Octave 함수의 개요가 있습니다. 다음 코드를 작성하여 5 x 5 항등 행렬을 반환하도록 수정하십시오.
| A = eye(5); |
끝 내면 ex1.m을 실행합니다. (올바른 디렉토리에 있다고 가정하고 Octave 프롬프트에서 "ex1"을 입력하십시오) 그러면 다음과 비슷한 출력이 표시됩니다.
ans =
Diagonal Matrix
1
0 0 0 0
0 1 0 0 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1
이 제 ex1.m은 아무 키나 누를 때까지 일시 중지 된 다음 할당의 다음 부분에 대한 코드를 실행합니다. 종료하고 싶다면, ctrl-c를 입력하면 실행 중에 프로그램이 중지됩니다.
2. 하나의 변수를 사용한 선형 회귀
이 실습의 이 부분에서는 식품 트럭의 생산성을 예측하기 위해 하나의 변수를 사용하여 선형 회귀를 구현합니다. 당신이 레스토랑 프랜차이즈의 CEO이고 새로운 매장을 여는 다른 도시를 고려한다고 가정 해보십시오. 체인에는 이미 여러 도시에 트럭이 있으며 도시의 인구와 인구에 대한 데이터가 있습니다.
이
데이터를 사용하여 다음 도시로 확장 할 도시를 선택할 수 있습니다.
ex1data1.txt 파일에는 선형 회귀 문제에 대한 데이터 집합이 포함되어 있습니다. 첫 번째 열은 도시의 인구이고 두
번째 열은 그 도시의 식품 트럭의 이익입니다. 이익의 음수 값은 손실을 나타냅니다.
ex1.m 스크립트가 이미이 데이터를 로드하도록 설정되었습니다.
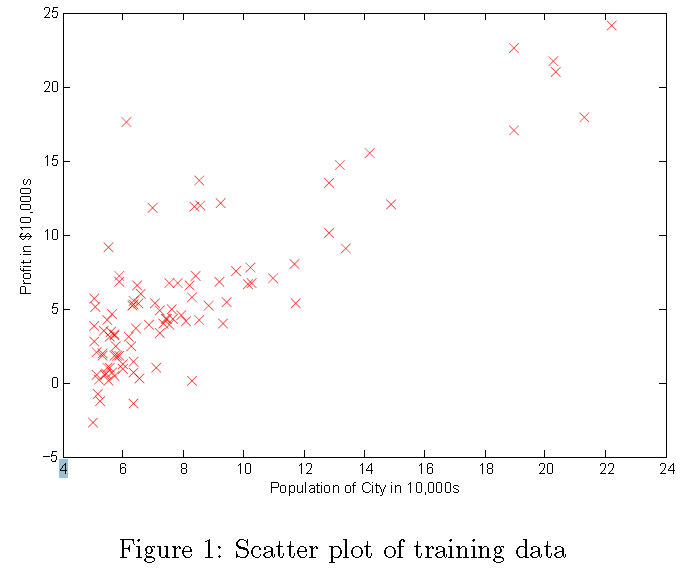
2.1 데이터 플로팅
어
떤 작업을 시작하기 전에 데이터를 시각화하여 이해하는 것이 유용합니다. 이 데이터 세트의 경우 데이터를 시각화하기 위해
산포도를 사용할 수 있습니다. 프로화일과 프로퍼티의 두 가지 속성 만 있으므로 데이터를 시각화 할 수 있습니다. (실생활에서
직면하게 될 다른 많은 문제는 다차원 적이기 때문에 2 차원 계획에 그려 질 수 없습니다.)
ex1.m에서 데이터 집합은 데이터 파일에서 변수 X와 y로 로드됩니다.
| data
= load('ex1data1.txt'); % read comma separated data X = data(:, 1); y = data(:, 2); m = length(y); % number of training examples |
그런 다음 스크립트는 plotData 함수를 호출하여 데이터의 산점도를 만듭니다. 당신의 임무는 플롯을 그리기 위해 플롯
Data.m을 완성하는 것입니다; 파일을 수정하고 다음 코드를 작성하십시오
| plot(x,
y, 'rx', 'MarkerSize', 10); % Plot the data ylabel('Profit in $10,000s'); % Set the y-axis label xlabel('Population of City in 10,000s'); % Set the x-axis label |
이제 ex1.m을 계속 실행하면 그림 1처럼 빨간색 "x"마커와 축 레이블이 나타납니다. plot 명령에 대한 자세한 내용은
Octave 명령 프롬프트에서 help plot을 입력하거나 문서를 플로팅 할 때 온라인에서 검색 할 수
있습니다. 마커를 빨간색 "x"로 변경하려면 plot 명령과 함께 'rx'옵션 (plot (.., [your
options here], ..,`rx ');)을 사용했습니다.
2.2 그라데이션 하강
이 부분에서는 그래디언트 디센트를 사용하여 데이터 집합에 대한 선형 회귀 매개 변수 θ를 지정합니다.
2.2.1 방정식 업데이트
선 형 회귀의 목적은 비용 함수를 최소화하는 것입니다.
여기서 가설 h (x)는 다음의 선형 모델에 의해 주어진다
모 델의 매개 변수는값 이라는 점을 상기하십시오. 비용 J(θ) 를 최소화하기 위해 조정할 값입니다. 이를 수행하는 한 가지 방법은 배치 그라디언트 디센트 알고리즘을 사용하는 것입니다. 배치 그라디언트 디센트에서 각 반복은 다음의 업데이트를 수행합니다.
(모든 j에 대해 θj를 동시에 업데이트)그라디언트 디센트의 각 단계에서 매개 변수 θj 는 최저 비용 J(θ) 를 달성 할 최적 값에 더 가까와 집니다.
구 현 참고 사항 : 각 예는 Octave의 X 행렬에 행으로 저장됩니다. 절편 (θ0) 을 고려하기 위해 X에 첫 번째 열을 추가하고 모든 것을 1로 설정합니다. 이것은 θ0 을 단순히 다른 '피처'로 취급 할 수있게 해줍니다.
2.2.2 구현
ex1.m 에서 선형 회귀에 대한 데이터를 이미 설정했습니다. 다음 줄에서는 θ0 절편을 수용하기 위해 데이터에 다른 차원을 추가합니다. 또한 초기 매개 변수를 0으로, 학습률 알파를 0.01으로 초기화합니다.
| X
= [ones(m, 1), data(:,1)]; % Add a column of ones to x theta = zeros(2, 1); % initialize fitting parameters iterations = 1500; alpha = 0.01; |
2.2.3 비용 J(θ) 계산
비
용 함수 J(θ) 를
최소화하기 위해 그래디언트 디센트를 수행 할 때 비용을 계산하여 수렴을 모니터링하는 것이 좋습니다. 이 섹션에서는 J(θ)
를 계산하는 함수를 구현하여 그래디언트 강하 구현의 수렴을 확인할 수 있습니다.
다음 작업은 J(θ)
를 계산하는 함수인 파일 computeCost.m에서 코드를 완성하는 것입니다. 이 작업을 수행함에 따라 변수 X와 y는
스칼라 값이 아니라 그 행들이 학습 집합의 예를 나타내는 행렬임을 기억하십시오.
이 함수를 완료하면 ex1.m의 다음 단계는 0으로 초기화 된 θ 를 사용하여 computeCost를 한 번 실행하여 화면에 인쇄 된 비용을 확인합니다. 약 32.07의 비용을 기대해야합니다.
하 나의 변수로 선형 회귀에 대해 "계산 비용"을 제출해야합니다.
2.2.4 경사 하강
다 음으로 파일 gradientDescent.m에 그라디언트 디센트를 구현합니다.루프 구조가 작성되었으며 각 반복 내에서만 업데이트를 제공하면됩니다.
프 로그램을 하면서 최적화하려는 내용과 업데이트되는 내용을 이해해야합니다. 비용 J(θ) 는 X와 y가 아닌, 벡터 θ 에 의해 매개 변수화됩니다. 즉, 우리는 X 또는 y를 변경하지 않고 벡터의 값을 변경하여 J(θ) 의 값을 최소화합니다. 불확실한 경우 이 유인물의 방정식과 비디오 강의를 참조하십시오.
그 래디언트 디센트가 올바르게 작동하는지 확인하는 좋은 방법은 J(θ) 의 값을 보고 각 단계마다 감소하는지 확인하는 것입니다. gradientDescent.m의 시작 코드는 모든 반복에서 computeCost를 호출하고 비용을 출력합니다. 그래디언트 디센트와 computeCost를 올바르게 구현했다고 가정하면 J(θ) 의 값은 절대로 증가해서는 안되며 알고리즘이 끝날 때까지 안정된 값으로 수렴되어야합니다.
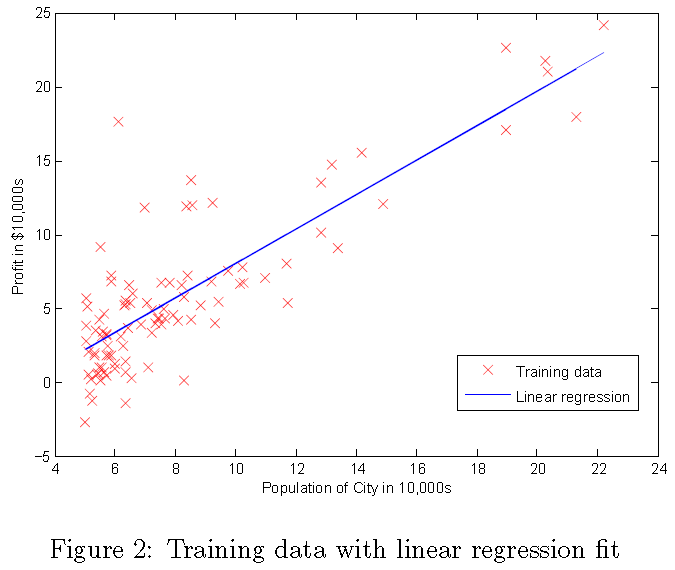
끝 내면 ex1.m은 선형 매개 변수를 그리기 위해 매개 변수를 사용합니다. 결과는 그림 2와 같을 것입니다 :
당 신의마지막 θ 값은 35,000 및 70,000 명의 사람들의 지역에 대한 이윤 예측에 사용됩니다. ex1.m의 다음 행은 명시적 합계 또는 반복이 아닌 행렬 곱셈을 사용하여 예측을 계산하는 방식에 유의하십시오. Octave의 코드 벡터화 예제입니다.
하 나의 변수로 선형 회귀에 대한 그래디언트 디센트를 제출해야합니다.
| predict1
= [1, 3.5] * theta; predict2 = [1, 7] * theta;7 |
2.3 디버깅
다 음은 그라디언트 디센트를 구현할 때 염두에 두어야 할 몇 가지 사항입니다.
• 옥타브 배열 인덱스는 0이 아닌 1부터 시작합니다. theta라는 벡터에 θ0과 θ1을 저장하면 값은 theta (1)와 theta (2)가됩니다.
• 런타임에 많은 오류가 나타나는 경우 행렬 작업을 검사하여 호환되는 차원의 행렬을 더하고 곱하는 지 확인하십시오. 크기 명령을 사용하여 변수의 크기를 인쇄하면 디버그하는 데 도움이됩니다.
• 기본적으로 Octave는 수학 연산자를 행렬 연산자로 해석합니다.이것은 크기 비호 환성 오류의 일반적인 원인입니다. 행렬 곱셈을 원하지 않으면 "도트"표기법을 추가하여 Octave에 지정해야합니다. 예를 들어, A * B는 행렬 곱셈을하는 반면, A.* B는 원소 단위의 곱셈을 수행합니다.
2.4 J(θ) 시각화
비 용 함수 J(θ) 를 더 잘 이해하기 위해 이제 θ0과 θ1 값의 2 차원 그리드에 대한 비용을 표시합니다. 이 부분에서 새로운 코드를 작성할 필요는 없지만 작성한 코드가 어떻게 작동하는지 이해해야합니다이미 이러한 이미지를 만들고 있습니다.
ex1.m 의 다음 단계에서는 작성한 computeCost 함수를 사용하여 값 표에 J(θ) 를 계산하도록 코드를 설정합니다.
| %
initialize J vals to a matrix of 0's J_vals = zeros(length(theta0 vals), length(theta1 vals)); % Fill out J vals for i = 1:length(theta0 vals) for j = 1:length(theta1 vals) t = [theta0 vals(i); theta1 vals(j)]; J_vals(i,j) = computeCost(x, y, t); end end |
이 행들이 실행 된 후에는 J(θ) 값의 2 차원 배열을가집니다.그런 다음 ex1.m 스크립트는이 값을 사용하여 surf 및 contour 명령을 사용하여 J(θ) 의 표면 및 윤곽 플롯을 생성합니다. 플롯은 그림 3과 같아야합니다
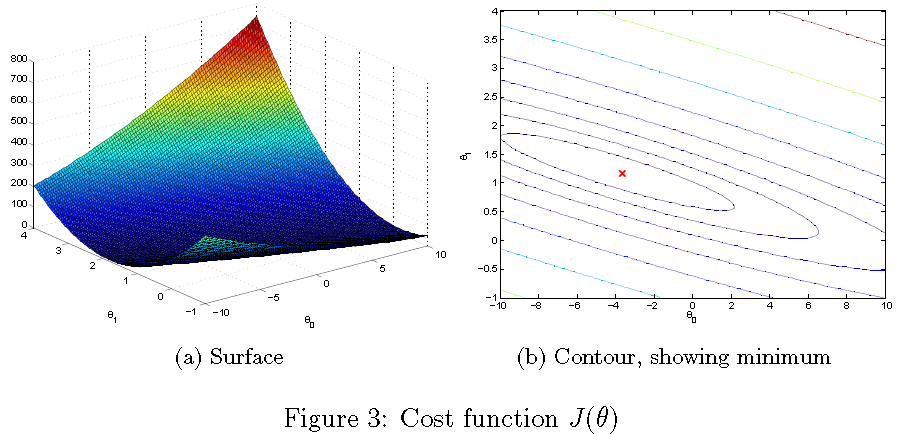
이 그래프의 목적은 J(θ) 가 θ0과 θ1 의 변화에 따라 어떻게 변하는지를 보여주는
것입니다. 비용 함수 J(θ) 는 사발 모양이며 전체 최소값을가집니다. 3D
등고선 플롯보다 윤곽 플롯에서 더 쉽게 볼 수 있습니다. 이 최소값은 θ0과 θ1 에 대한 최적의 점이며, 그래디언트 디센트의
각 단계는이 지점에 더 가깝게 이동합니다.
3 다중 변수를 이용한 선형 회귀
이 파트에서는 주택 가격을 예측하기 위해 여러 변수가 있는 선형 회귀 분석을 구현합니다. 당신이 당신의 집을 팔고 있고, 좋은 시장 가격이 무엇인지 알기를 원한다고 가정하십시오. 이를 수행하는 한 가지 방법은 최근 판매 된 주택에 대한 정보를 수집하고 주택 가격 모델을 만드는 것입니다.
파 일 ex1data2.txt 에는 오리건 주 포틀랜드에 있는 주택 가격에 대한 훈련 세트가 포함되어 있습니다. 첫 번째 열은 집 크기 (평방 피트), 두 번째 열은 침실 수, 세 번째 열은 주택 가격입니다.
이 연습을 수행하는 데 도움이 되는 ex1 multi.m 스크립트가 설정되었습니다.
3.1 특징 정규화
ex1 multi.m 스크립트는 이 데이터 세트의 일부 값을 로드하고 표시하여 시작합니다. 값을 살펴보면 집 크기는 침실 수의 약 1000 배입니다. 특징의 크기가 커지면 먼저 피쳐 스케일링을 수행하면 그래디언트 디센트가 훨씬 더 빠르게 수렴됩니다.
여 기에서의 작업은 featureNormalize.m에서 코드를 완료하는 것입니다.
• 데이터 세트에서 각 특징의 평균값을 뺍니다.
• 평균을 빼면 각 "표준 편차"로 특성 값을 추가로 스케일 (나눗셈)합니다.
표 준 편차는 특정 특징의 값 범위에 얼마나 많은 변동이 있는지 측정하는 방법입니다 (대부분의 데이터 요소는 평균의 2 표준 편차 이내입니다). 이것은 값 범위 (max-min)를 취하는 것의 대안입니다. Octave에서는 표준 편차를 계산하기 위해 "std" 함수를 사용할 수 있습니다. 예를 들어, featureNormalize.m 내에서 X (:, 1)에는 학습 집합의 x1 (집 크기)의 모든 값이 포함되므로 std (X (:, 1))은 집 크기의 표준 편차를 계산합니다.featureNormalize.m이 호출 될 때 x0 = 1에 해당하는 1의 추가 열이 아직 X에 추가되지 않았습니다 (자세한 내용은 ex1 multi.m 참조).
모 든 특징에 대해 이 작업을 수행하며 코드는 모든 크기의 데이터 세트 (여러 가지 기능 / 예제)에서 작동해야 합니다. 행렬 X의 각 열은 하나의 특성에 해당합니다.
이 제 정규화를 제출해야합니다.
| 구 현 참고 사항 : 특징을 정규화 할 때, 정규화에 사용 된 값 - 계산에 사용 된 평균값과 표준 편차를 저장하는 것이 중요합니다. 모델에서 매개 변수를 학습 한 후에 우리는 이전에 보지 못한 주택 가격을 예측하기를 원합니다. 새로운 x 값 (거실 공간 및 침실 수)이 주어지면, 우리는 먼저 훈련 세트에서 계산 한 평균 및 표준 편차를 사용하여 x를 표준화해야 합니다. |
3.2 그라데이션 하강
이 전에는 단 변량 회귀 문제에 그라디언트 디센트를 구현했습니다. 유일한 차이점은 행렬 X에 또 하나의 특징이 있다는 것입니다. 가설 함수와 배치 구배 하강 업데이트 규칙은 변경되지 않습니다.
computeCostMulti.m 및 gradientDescentMulti.m의 코드를 완료하여 여러 변수가 있는 선형 회귀에 대한 비용 함수와 그라디언트 디센트를 구현해야 합니다. 이전 부분 (단일 변수)의 코드가 이미 여러 변수를 지원하는 경우 여기에서도 사용할 수 있습니다.
코 드가 여러 가지 기능을 지원하고 잘 벡터화되어 있는지 확인하십시오. `size (X, 2) '를 사용하여 데이터 세트에 존재하는 특징의 개수를 알 수 있습니다.
이 제 다중 변수가 있는 선형 회귀에 대한 계산 비용 및 그래디언트 디센트를 제출해야합니다.
|
구 현 참고 사항 : 다 변수의 경우 비용 함수는 다음 벡터 형식으로 작성할 수도 있습니다.
여 기에서
|


3.2.1 학습 속도 선택
이 부분에서는 데이터 집합에 대해 다른 학습 속도를 시도하고 빠르게 수렴되는 학습 속도를 얻게됩니다. ex1 multi.m을 수정하고 학습 속도를 설정하는 코드 부분을 변경하여 학습 속도를 변경할 수 있습니다.ex1 multi.m의
다 음 단계는 gradientDescent.m 함수를 호출하고 선택된 학습 속도로 약 50 회 반복하여 그라디언트 디센트를 실행합니다. 이 함수는 벡터 J에서 J(θ ) 값의 이력을 반환해야 합니다. 마지막 반복 후 ex1 multi.m 스크립트는 J 값을 반복 횟수에 대해 그립니다.
좋 은 범위 내에서 학습률을 고른 경우 플롯이 유사하게 보입니다. 그래프가 매우 다른 경우, 특히 J(θ) 값이 증가하거나 폭발하면 학습 속도를 조정하고 다시 시도하십시오. 학습 속도 값은 이전 값 (예 : 0.3, 0.1, 0.03, 0.01 등)의 약 3 배의 곱셈 단계로 로그 배율로 시도하는 것이 좋습니다. 또한 커브의 전반적인 경향을 파악하는 데 도움이 될 경우 실행 중인 반복 횟수를 조정할 수도 있습니다.

| 구 현 참고 사항 : 학습 속도가 너무 높으면 J(θ) 가 분산되어 '폭발'할 수있어 결과가 컴퓨터 계산에 비해 너무 커집니다. 이러한 상황에서 Octave는 NaN을 반환하는 경향이 있습니다. NaN은 '숫자가 아닙니다'의 약자이며 -∞ 및 +∞ 이 포함 된 정의되지 않은 연산으로 인해 발생합니다. |
|
옥 타브 팁 : 다른 학습 학습 속도가 수렴에 미치는 영향을 비교하기 위해 J를 같은 그림에 몇 가지 학습 속도로 구하는 것이 도움이됩니다. Octave에서는 플롯간에`hold on '명령으로 여러 번 그라디언트 디센트를 수행하면됩니다. 구체적으로, 세 가지 다른 알파 값 (이 값보다 많은 값을 시도해야 함)을 사용하고 J1, J2 및 J3에 비용을 저장 한 경우 다음 명령을 사용하여 같은 값으로 그 값을 그릴 수 있습니다. plot(1:50,
J1 (1:50), b '); 마 지막 인자`b ',`r',`k '는 그 그림의 색깔을 다르게 지정한다. |
학 습률이 변함에 따라 수렴 곡선의 변화를 확인하십시오. 학습률이 낮 으면 그레디언트 디센트가 최적의 값으로 수렴하는 데 오랜 시간이 걸린다는 사실을 알아야합니다. 반대로, 학습 속도가 빠르면 그라디언트 디센트가 수렴하지 않거나 분기 될 수 있습니다.
가 장 좋은 학습 률을 사용하여 ex1 multi.m 스크립트를 실행하여 융합이 될 때까지 그라디언트 디센트를 실행하여 최종 값을 찾습니다. 다음으로,이 값을 사용하여 1650 평방 피트 및 침실이 3 개인 집 가격을 예측합니다. 나중에 값을 사용하여 정상 방정식의 구현을 점검 할 것입니다. 이 예측을 할 때 기능을 정상화하는 것을 잊지 마십시오!
이 선택적 (비평 행) 애플리케이션에 대한 솔루션을 제출할 필요는 없습니다.수업 과정.
3.3 정규 방정식
강 의 비디오에서 선형 회귀에 대한 닫힌 형식의 해는:

이 수식을 사용하면 어떤 기능 확장도 필요 없으며 한 번의 계산으로 정확한 솔루션을 얻을 수 있습니다. 즉, 수렴되기 전까지 루프가 없습니다 (예 : 그라디언트 디센트).
위 공식을 사용하여 계산하려면 normalEqn.m의 코드를 완성하십시오. 기능을 확장 할 필요는 없지만 절편 (0)을 사용하려면 X 행렬에 1의 열을 추가해야합니다.ex1.m의 코드는 1의 열을 X에 추가합니다.
이 제 정규 방정식 함수를 제출해야합니다.
선 택 사항 (비 격렬한) 운동 : 이제이 방법을 사용하면 3 개의 침실이있는 1650 제곱미터 규모의 주택에 대한 가격 예측을 할 수 있습니다. 그라디언트 디센트 (3.2.1 절 참조)가있는 모델 t를 사용하여 얻은 값과 동일한 예측 가격을 제공해야합니다.